Data Science 관련 사이트로 유명한 Kaggle의 튜토리얼인 타이타닉 생존자 예측 과정을 통해 어떤 과정으로 진행해가면 좋을지 감을 잡아보려한다.
link : www.kaggle.com/c/titanic/overview
1. 데이터 다운로드 및 탐색
-> 위 링크의 데이터 섹션에서 Download All을 한 후 데이터를 탐색해본다.
1) 데이터를 정상적으로 불러온지를 확인하고 구경(?)하기 위한 head() 명령어

2) 각 데이터 컬럼들이 어떤것들이 있는지를 탐색
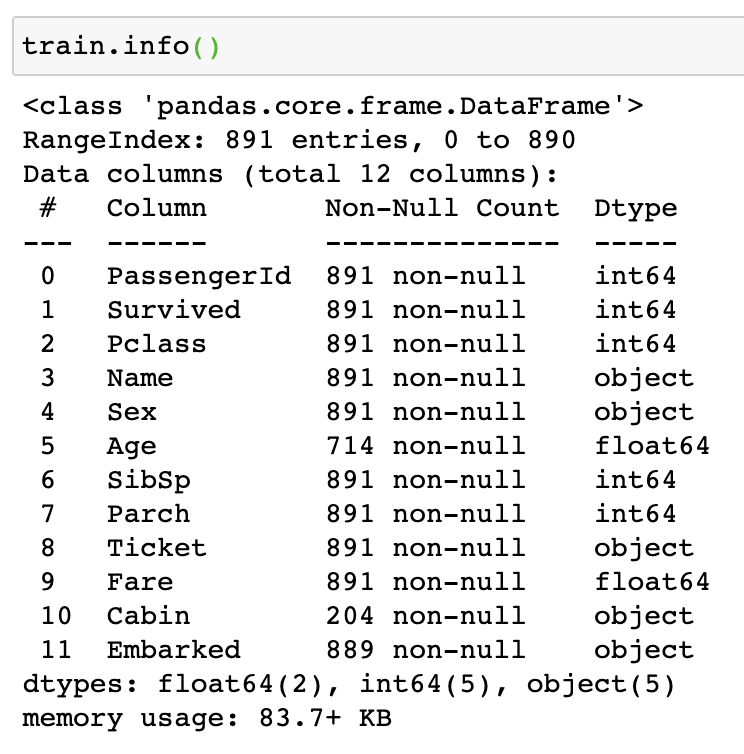
-> Train Set 에는 아래와 같이 총 12 개의 컬럼이 존재한다. 그 중 11개는 feature, Survived 는 생존 여부를 알려주는 Label이다.

아래 info 를 보면, Cabin 과 Age 데이터에 Null 데이터가 다수 존재하는 것을 알 수 있다. 해당 컬럼들에 대해 적절한 값을 추가해줄지 여부도 고려사항이다. 하지만, Cabin등의 값들은 결과에 대해 큰 영향을 주진 않을듯 하여 아예 drop 하는 것도 염두에 둘 필요가 있다.
3) 데이터 가공
일단, 직관적으로 사람들의 이름의 결혼 여부를 알려주는 정보들이 중요할 것이라 생각해 Name 데이터 처리 & 성별 데이터를 전처리 후 Int 값으로 수정하였다.
또한 Age 데이터에 Nan 값들에 대한 처리를 우선은 단순 Group By로 채워넣었다.

아래처럼 Embarked 값도 정수형으로 변환하고 나면 간단한 모델링 구현을 위한 데이터 전처리 작업은 끝나게된다.

2. Modeling 및 예측
간단한 케라스 코드를 통해 예측 모델을 생성하고, Kaggle에 올려본 결과 67% 가 나왔다. 생각보다 저조한 결과가 나와 당황스럽지만 좀 더 전처리와 모델링에 신경쓰고 시도해보려한다.


Denken_Y
coding 블로그